Learning Content & Research-Based Teaching
Student Project Showcase
How Words Are Built in the Mind:
A Case Study on Morphology, Meaning, and Stress Interplay in Slovene -ica Derivations
by Ema Štarkl (University of Graz / University of Ljubljana)
Have you ever wondered about the inner structure of words used every day during speech? Chances are you haven’t. But hear me out. Linguists have been trying to figure out all sorts of things about language as a human phenomenon to ultimately draw conclusions about how our brain works and even what it means to be a human. Studying words’ structure is a separate field within general linguistics and is called morphology.
As a student of linguistics, I have been particularly interested in morphology and I have recently worked on a project while attending a research-based class given by Marko Simonović who was also my mentor. I created this blog post not only to present this project, but also to illustrate what it means to be a theoretical linguist: What are the questions we are interested in, and how do we try to answer them?
In the blog post, I present how I analysed Slovene words and their structures to see how they are seen by the brain. It is not yet fully known what greater outcomes the linguistic research findings may lead to. However, examining smaller phenomena from various languages to see the bigger picture about language brings a better understanding of us and the world around us.
Words, Stress, and Radical Cores
Before diving into the specifics of Slovene morphology, there are some terms to be clarified. As you might have guessed by the introduction, words are not indivisible and have internal structures. They are compiled of different, smaller units, called morphemes. How these morphemes are compiled together has consequences on meaning and stress, among others. For this to be the most clear and understandable, I filmed a short introductory video, in which these relations between word structures and words as they are pronounced and understood are explained in more detail.
Word Derivations and Stress
Up to now, I have established the predictions regarding the likely morphological structures of three types of words. The words in group 1 are more likely to be decategorial derivations because of the presence of more than one morpheme before -ica. If there are more morphemes in a word, there is a higher chance that there is a (silent) categorial head already present in the word before -ica. The same prediction holds for the diminutives within group 2. Since their meaning is completely predictable, they are most likely derived from previously existing words and thus most likely to be decategorial derivations (recall that for a word to exist, there must be a categorial head present). The opposite prediction holds for the words with idiosyncratic meanings within group 2. They are most likely to be deradical derivations.
According to Simonović, deradical derivations can have suffix stress and decategorial ones cannot. If this is correct, we expect the three groups’ stress placements to differ significantly. To be precise, the idiosyncratic derivations within group 2 are expected to have significantly more suffix stress than either the diminutives within group 2 and the words of group 1.
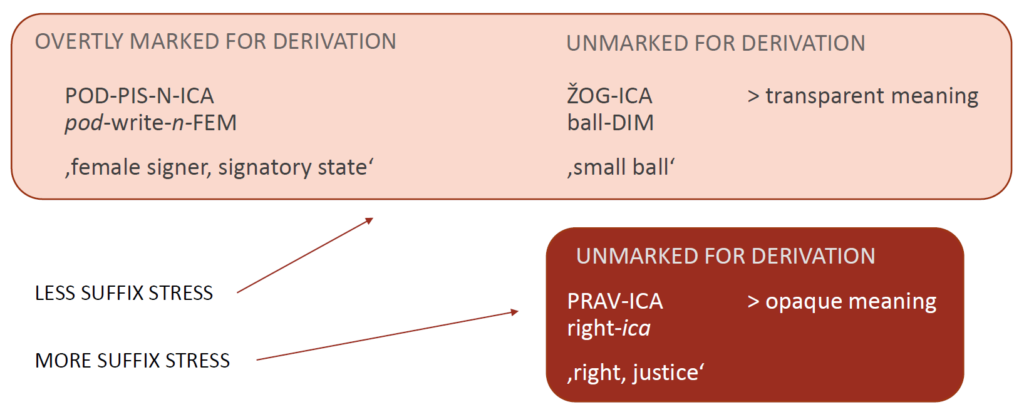
Figure 1. The sample and the stress predictions
Research Questions
To test Simonović’s hypothesis, I have formulated the following research questions:
- Does the presence of more morphemes entail stress placement before -ica? In other words, do the words from group 1 have significantly less suffix stress than words from group 2?
- Does meaning transparency entail stress placements before? Specifically, do the diminutives of group 2 have significantly less suffix stress than the idiosyncratic derivations of group 2?
- Is the connection of stress away from -ica stronger when both factors are combined? In other words, do the words of group 1 and the diminutives of group 2 on the one hand have significantly less suffix stress than the idiosyncratic derivations of group 2 on the other hand?
Different Words, Different Structures
As presented in the introductory video, Simonović (2020, to appear) claims that stress placement in Slovene words depends on the underlying morphological structure. If the affix is attached within the radical core, it can be stressed. If it falls out of the radical core, it cannot.
It is important to test broader claims with smaller case studies because this could lead to new findings further supporting or challenging the claims. Therefore, I decided to test Simonović’s (2020, to appear) account focused on a specific native Slovene suffix –ica, which is used in different types of derivations.
The suffix can either be attached to a base containing more than one overt morpheme (see 1, I will call this group of words group 1) or bases in which only the root is overt (see 2, group 2). According to Simonović’s account, it is expected for the words of group 1 (example 1) to be more likely to be derived decategorially and the words of group 2 (example 2) to tend to be derived deradically. It should thus also be anticipated for the former to have less stress on -ica than the latter. We also expect the latter group to be heterogeneous in terms of stress, since words can be formed decategorially with unpronounced categorial heads.
(1) a. vodíteljica
vod-i-telj-ica
lead-tv-telj-fem
‘female leader, female radio/TV presenter’
b. podpísnica
pod-pis-n-ica
pod-write-n-fem
‘female signer, signatory state’
(2) a. pravíca
prav-ica
right-ica
‘right, justice’
b. žógica
žog-ica
ball-dim
‘little ball’
Addressing the anticipated stress placements in the group unmarked for derivation, its heterogeneity is not expected to be random. Aside from stress, another indicator of the morphological structure of words can be their meaning; decategorial derivations have predictable / transparent / decomposable meanings. This means we can know the meaning of the composed word if only we know the meanings of each component. Deradical derivations, on the other hand, have unpredictable / opaque / idiosyncratic meanings. In their case, it is not clear what meaning the suffix brings to the derived word. (Marantz 2001, Marvin 2002, Arad 2003) Each composite is nonetheless recognizable by the speakers.
In this blog post, I focus on two different types of derivations within group 2 in connection to the predictability of their meanings. One of them contains idiosyncratic derivations, which are likely to be deradical derivations (see example 2a). The other contains diminutives, which have completely decomposable meaning and are thus likely to be decategorial derivations (see example 2b). The distinction between diminutives on the one hand and the idiosyncratic derivations on the other is used as an outside indicator of the underlying morphological structures aside from stress. A major deviation from a correlation between the two predictors would be a challenge for the analysis provided by Simonović.
The Sample
To answer my research questions, I use standard Slovene corpus data, extracted from the Gigafida 2.0 corpus (available at www.gigafida.net, Logar Berginc et al. 2012) using noSketch Engine hosted by CLARIN.SI. I used this dataset because it is one of the largest Slovene datasets, which is easily searchable and it includes a variety of different text sources, providing a varied and non-skewed selection of words to be used as a sample.
My final sample includes 583 target words with a mean frequency of 10.4 per million, a median of 3.2, mode 1.8 and a standard deviation of 26,1; the maximum frequency is 344.5 and the minimum 0 per million.
I organized the corpus data in an Excel table and annotated all words for stress (1 if stressed on -ica and 0 if not), frequency, and whether the word belongs to group 1 or group 2 (1 for group 1 and 0 for group 2). Within group 2, I further differentiated between two groups: i) the diminutives (annotated 1 in the diminutive column) and ii) the idiosyncratic derivations (annotated 0 in the diminutive column). Here I present a section of the table to illustrate how such a database may look. Examples 1–3 belong to group 1 and examples 4–9 belong to group 2. Within group 2, examples 4–6 are the idiosyncratic derivations and examples 7–9 are diminutives. In the section of the table below, I have also added English translations.
Table 1: The sample of the database
| word | frequency | stress | group_1 | diminutive | translation |
| klet-v-ica | 2,16 | 0 | 1 | N/A | “curse word” |
| vod-i-telj-ica | 16,73 | 0 | 1 | N/A | “female presenter” |
| pod-pis-n-ica | 3,24 | 0 | 1 | N/A | “female signer, signatory state” |
| prav-ica | 344,49 | 1 | 0 | 0 | “right, justice” |
| črn-ica | 0,44 | 1 | 0 | 0 | “black soil” |
| ul-ica | 150,37 | 0 | 0 | 0 | “street” |
| stez-ica | 1,79 | 1 | 0 | 1 | “small path” |
| glav-ica | 3,95 | 0 | 0 | 1 | “small head” |
| žog-ica | 11,34 | 0 | 0 | 1 | “small ball” |
Results
To answer my research questions, I statistically analysed my data to fit into generalized linear mixed models in the programme R. Table 2 below shows a summary of the results.
| Table 2: Predictability of stress depending on whether the word belongs to group 1 or group 2 | |||||
| Estimate | Standard Error | z value | Pr(>|z|) | p value | |
| Group 2 | -11.05 | 6.458e-04 | -17113 | <2e-16 | <0.001 |
| Group 1 | -14.88 | 6.457e-04 | -23038 | <2e-16 | <0.001 |
The estimated value of group 1 is lower than the one of group 2. This means that the words belonging to group 1 are less likely to have suffix stress. It is now very important to see whether this difference between the group is statistically significant. This is indicated by the p-value. If it is lower than 0.05, the difference is significant. Here the values are much lower, which means that the difference is very significant. We can be almost certain that the difference did not occur by chance, and it would still be there if we would test all Slovene -ica derivations that exist. That is, of course, very difficult if not impossible and this is exactly the reason why we use smaller samples. Question 1 can thus be answered positively. The words from group 1 do indeed have significantly less suffix stress than words from group 2.
| Table 3: Predictability of stress depending on semantic factors in group 2 | |||||
| Estimate | Standard Error | z value | Pr(>|z|) | p value | |
| Idiosyncratic derivations | 0.8473 | 0.2817 | 3.007 | 0.00263 | 0.001 |
| Diminutives | -2.8306 | 0.3940 | -7.184 | 6.79e-13 | <0.001 |
The positive estimate value of the idiosyncratic derivations tells us that they are likely to be stressed on -ica, and the negative value of the diminutives tells us that they are not likely to be stressed on -ica. Both observations are statistically significant since the p-values are lower than 0.05. Question 2 can thus be answered positively as well. The diminutives of group 2 do indeed have significantly less suffix stress than the idiosyncratic derivations of group 2. What is more, the idiosyncratic derivations are in fact really likely to have suffix stress whereas the opposite holds for diminutives.
| Table 4: Predictability of stress considering both morphological and meaning factors | |||||
| Estimate | Standard Error | z value | Pr(>|z|) | p value | |
| Idiosyncratic | 10.480 | 1.221 | 8.585 | <2e-16 | <0.001 |
| Both factors | -22.892 | 1.837 | -12.461 | <2e-16 | <0.001 |
Here, the idiosyncratic group represents the group of words which have no outside factors indicating that the derivation might be decategorial – neither do they have more than one morpheme before –ica nor is their meaning predictable. The other group are the rest of the words, which are either members of group 1 or diminutives. The idiosyncratic derivations are significantly likely to have suffix stress and the other words are significantly unlikely to have suffix stress. This difference between the Estimates is much bigger than in the previous two analyses. Finally, the third research question can be answered positively.
The analyses have brought additional support for Simonovć (2020, to appear). The two indicators of morphological structure (in particular, the type of derivation – deradical or decategorial), namely the presence of more than one overt morpheme before -ica and the predictability of meaning turned out to be statistically significant predictors of stress placement in Slovene -ica derivations. This means that stress placement indicates the same underlying morphological structure as the previously known predictors. According to my project, stress placement thus depends on the underlying morphological structure and can be used as its indicator.
Linguistic Experiments and How I Designed Mine
Simovonič’s account which claims that stress depends on the inner morphological structure of words has been confirmed using a corpus sample. But this is not enough to argue that these structures are active – productive in the minds of today’s speakers. It could be the case that the stress placements are simply learned for each individual word, and they stem from a previous speakers’ interpretations.
To test whether something is productive in a language, one would need to have a direct look into the brains of the speakers. This is pretty much impossible (for now), but there are ways in which researchers can observe the brain’s processes indirectly. One of these ways are linguistic experiments. Carefully designed to provide answers to very specific linguistic questions, they are one of the most powerful tools scholars have to examine language. There are many different types of linguistic experiments, but they all share the fact that they require special attention during the design phase.
In the following videos I explain some general information about conducting experiments, which leads me to presenting an experiment I designed to further test the generalizations made in this blog post so far.
Experiments, Internalised Grammars, and Pseudo-Words
The question of whether something is productive or in other words, whether it is in fact really present in the minds of today’s speakers, is a central one in linguistics. The stress placements in existing words were there before the speakers who are alive today. It could well be the case that the differences in stress are learned and do not stem from the different underlying structures, at least not in the minds of the speakers alive today.
The speakers of languages have internalised language systems – grammars in their minds. They can judge linguistic expressions or complete various tasks, which are carefully developed by linguists. The speakers’ answers can give researchers an indirect view of the internalised grammars. Many people do not know that the main goal of theoretical general linguistics is in fact studying speakers’ internalised grammars to determine the mechanisms of language as a phenomenon.
Testing the Speakers’ Minds
To experimentally test the minds of the speakers of Slovene and examine whether the structures proposed by Simonović and this project are productive, I designed a set of pseudo-words. Fake words, which are similar to real ones. I carefully picked the morphemes to make intended structures apparent. The fake words can be put into sentences and be read by Slovene speakers. They need to decide where to stress the words on the spot – they have never seen them before since I made them up. In this video, I outline this process in more detail. If you are detail-oriented and want food for your linguistic thought, this one is for you.
Conclusion
I am grateful to have had the chance to work on this project, present it in front of an audience (video of my presentation is available here), and publish it as a blog post. I worked with my mentor Marko Simonović, dealt with new topics and examined a phenomenon in my native language to gain insight into language as a whole. The project leaves open many questions and possibilities for future work and will thus most definitely help me develop professionally. I am thankful to the UPSKILLS project and all the people who made it possible for me. Hopefully, the insight into linguistic work through this study might spark new interests or feed some curiosity also for the reader.
References
Arad, M. (2003). Locality constraints on the interpretations of roots. Natural Language and Linguistic Theory 21. 737–78.
Halle, M. and Marantz, A. (1993). Distributed morphology and the pieces of inflection. In Hale, K. and Keyser, S. J., editors, The View from Building 20, pages 111–176. MIT Press, Cambridge, MA.
Halle, M. and Marantz, A. (1994). Some key features of distributed morphology. In Carnie, A. and Harley, H., editors, MITWPL 21: Papers on phonology and morphology, pages 275–288. MITWPL, Cambridge, MA.
Karta slovenskih narečij z večjimi naselji. (2016) (The map developed by Tine Logar and Jakob Rigler (1983) was updated by the associates of the Dialectological Section of the Fran Ramovš Institute of the Slovenian Language ZRC SAZU). Available online: https://fran.si/204/sla-slovenski-lingvisticni-atlas/datoteke/SLA_Karta-narecij.pdf
Logar Berginc, N., Grčar, M., Brakus, M., Erjavec, T., Arhar Holdt, Š., and Krek, S. (2012). Korpusi slovenskega jezika Gigafida, KRES, ccGigafida in ccKRES: gradnja, vsebina, uporaba. Ljubljana: Trojina, zavod za uporabno slovenistiko, Fakulteta za družbene vede. Available online.
Lowenstamm, J. (2014). Derivational affixes as roots: Phasal Spell-out meets English Stress Shift. In Alexiadou, A., Borer, H., and Schäfer, F., editors, The Syntax of Roots and the Roots of Syntax. Oxford University Press, Oxford. 230–259.
Marantz, A. (2001). Words. MS, Massachusetts Institute of Technology.
Marvin, T. 2002. Topics in the Stress and Syntax of Words. Cambridge (MA): MIT Working Papers in Linguistics.
Simonović, M. (2020). Categories, Root Complexes and Default Stress: Slovenian Nominalizations Revisited. Linguistica, 60(1). 103–117.
Simonović, M. (to appear). Derivational affixes as roots across categories. Journal of Slavic Linguistics.

Ema Štarkl
I am an MA general linguistics student at University of Ljubljana, Slovenia, where I am currently working on my masters thesis. I finished BA studies in general linguistics and Slovene studies at University of Ljubljana in 2020. I graduated on the topic of the morphosyntax of verbs in Slovenian Celje urban dialect. I recently took a semester abroad in Graz, Austria, where I worked on the Hyperspacing the verb project. At the moment, I focus my research mostly on Slovene morphosyntax in the scope of generative linguistics and Slovene dialectology.